FIBRE CHANNEL PERFORMANCES WITH IBM EQUIPMENT
Figures 2 (right), 3, 4 and 5 display the performances for writing data on the sender side with and without the Fabric. For small messages (less than 1Kbytes), the socket buffer size was set to 1 Kbytes for this test. For large messages, the socket buffer size was set to 1 Mbytes and the -D option (TCP_nodelay) was set off.
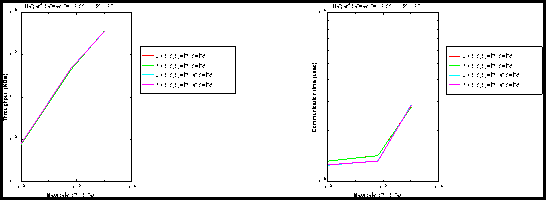
Figure 1: From memory to memory: (left) Throughput, (right) Communication latency.
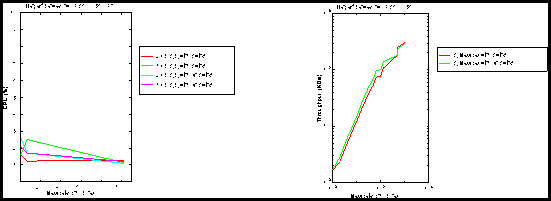
Figure 2:(left) CPU (From memory to memory), (right) Throughput (small messages).
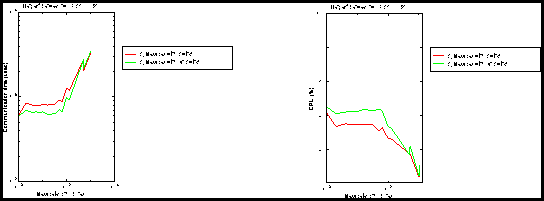
Figure 3: (left) Overhead (small messages), (right) CPU (small messages).
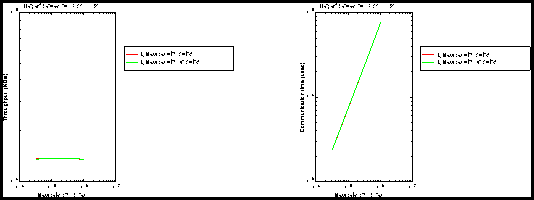
Figure 4: (left) Throughput (large messages), (right) Overhead (large messages).
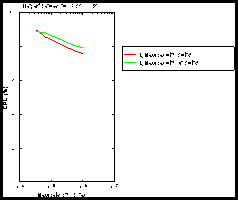
Figure 5: (CPU) (large messages).
From memory to memory performance measurements (see figure 1 (right)), we can infer the following Fabric latency:
The last value (the negative one) is strange and difficult to explain but is found consistently. In other words, it means that when the Fabric is located between two workstations, it improves the communication performance for messages greater than 512 bytes.
Hereinafter is the summary of the critical performances that have been measured:
For large messages, there is practically no difference in performances when the communication is performed with or without the Fabric. On the contrary, for small messages, the best performances are measured for back to back communications.
The influence of the switch is that:
Generated with CERN WebMaker