The communication results can only be put into perspective if the communication load to the processor is known. Consequently, we have also performed load measurements. The load is measured by concurrent execution of a communication task and a computation task on each of the two processors. The computation task measures the remaining processor power. It does this by increasing a counter in memory. By measuring the counter increase per second on an unloaded system beforehand, we can determine the processor load in a system with communication.
In Linux, there are two facilities to execute a task: processes and threads. Each process has its own memory space, which keeps all other processes from accessing this memory. Threads exist within processes, sharing the memory space of the process. Memory spaces are mapped onto physical memory by the Memory Management Unit (MMU) of the processor. Context switching requires changing the mapping of the MMU. Since threads of the same process use the same mapping, context switching between these threads takes less CPU time than context switching between processes.
The amount of time available for a process depends on the amount of time assigned to it by the scheduler. To avoid suffering of the communication process from the calculation process, a high priority real-time scheduling strategy is used for the communication process. This strategy should make sure that the communication process gets scheduled-in as soon as work for it is available, i.e., at the moment the blocking communication has finished.
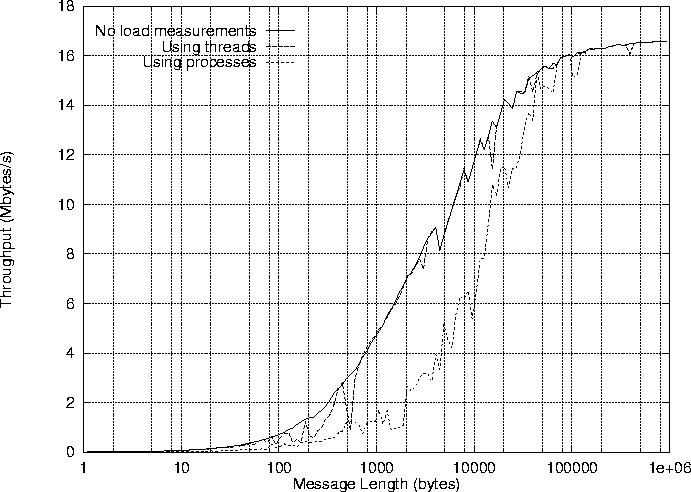
Figure 11: The effect of computation on the throughput for different message lengths, Comms2 and maximum packet size 4096.
Figure 11 shows three Comms2 throughput graphs: without computation, computation by a thread, and computation by a process. The graphs show that using concurrent threads has little impact on the communication, and that using processes has a significant impact. We can estimate this impact by using a quantification based on the Comms1 and 2 linear timing model[9]:
![]()
![]()
In this model, ![]() is the latency for a message of size n;
is the latency for a message of size n; ![]() is the latency to send a zero byte message;
is the latency to send a zero byte message; ![]() is the throughput;
and
is the throughput;
and ![]() is the asymptotic bandwidth, i.e.,
is the asymptotic bandwidth, i.e., ![]() , the limit on the maximum
throughput. From this model one can derive that:
, the limit on the maximum
throughput. From this model one can derive that:
![]()
The value ![]() is the half-performance message length, i.e., the
message length required to achieve half the asymptotic bandwidth.
Knowing
is the half-performance message length, i.e., the
message length required to achieve half the asymptotic bandwidth.
Knowing ![]() , we can estimate
, we can estimate ![]() , by
obtaining
, by
obtaining ![]() from the throughput graphs in
Figure 11. These estimations, see
Table 2, show that the context switching
overhead due to the use of processes instead of threads is
significant: a difference of about 600
from the throughput graphs in
Figure 11. These estimations, see
Table 2, show that the context switching
overhead due to the use of processes instead of threads is
significant: a difference of about 600 ![]() s in
s in ![]() . The
T9000 results, which are also included in this table, show how the
T9000 outperforms the DSNIC with respect to 0-byte message latency.
. The
T9000 results, which are also included in this table, show how the
T9000 outperforms the DSNIC with respect to 0-byte message latency.
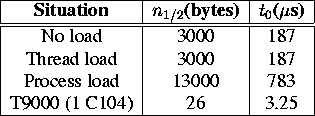
Table 2: Estimations of the 0-byte message latency ![]() , for Comms2 and packet size 4096.
, for Comms2 and packet size 4096.
The CPU load of both the process and the thread version are similar for long messages. This is to be expected: for large messages few process switches need to be performed because the communication task is nearly continuously sleeping, so the load is caused by interrupt handling which is identical in both situations. In that case, the interrupt frequency, which is directly related to the packet size, has a major effect on the load.
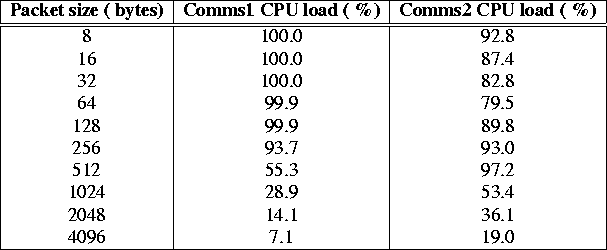
Table 3: Maximum CPU load for long messages.
Table 3 shows the maximum CPU load measured during
Comms1 and Comms2 for 0.5 Mb up to 1 Mb messages. For
Comms1, we see that the CPU load roughly doubles if the packet size
halves, so packet size ![]() load =
constant. According to this formula, the constant is
the packet size at which the CPU load would be 100 % to
achieve full bandwidth utilisation. Using packet sizes smaller than
the constant will not allow full bandwidth utilisation. For
Comms1, the constant is approximately 290 for packet sizes of
512 and more. The 290 indicates that the maximum throughput cannot
be reached with packet size 256, as we have seen
before. Furthermore, the 290 corresponds to the end of the
throughput dip in Comms1, where the expected throughput is reached
again, see
Figure 6.
load =
constant. According to this formula, the constant is
the packet size at which the CPU load would be 100 % to
achieve full bandwidth utilisation. Using packet sizes smaller than
the constant will not allow full bandwidth utilisation. For
Comms1, the constant is approximately 290 for packet sizes of
512 and more. The 290 indicates that the maximum throughput cannot
be reached with packet size 256, as we have seen
before. Furthermore, the 290 corresponds to the end of the
throughput dip in Comms1, where the expected throughput is reached
again, see
Figure 6.