FIBRE CHANNEL PERFORMANCES WITH IBM EQUIPMENT
As part of the preparatory program for LHC experimentation, various Research and Development projects have been set up around detectors, associated electronics, and data acquisition. In this proposed joint project, we are directly concerned with the activities in the R&D project EAST (RD-11), presently involved in several pilot projects to demonstrate the critical components of such a selection ("trigger") system at an input rate of 100 kHz. EAST has evolved the basic Region of Interest concept (RoI) for Second level Triggering. A RoI represents a spatial area in the subdetector, in which the previous level of triggering (i.e. first level) has identified candidates for interesting phenomena to be triggered.
In this scheme, EAST has decomposed the Second level Trigger problem into three different phases, in order to implement it. Phase 1 deals with front-end buffering and RoI collection. Phase 2, named Feature Extraction, is relative to some Local Processing of data inside a RoI of a subdetector. Phase 3 is devoted to Global Decision: Physics features will have to be collected from all subdetectors and from all RoIs in order to allow to take an overall decision on the entire event.
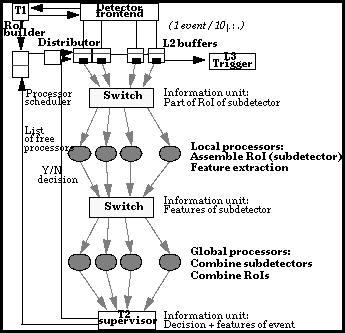
Basic choices exist in expressing the implementation of these three phases as architectures, for which we consider processor architectures based on more or less commercial massively parallel computing elements and high-bandwidth data transmission, on image processing devices, and on FPGA-based architectures. One possible architecture choice is based on the well known farm-approach and will use only standard commercial devices, general purpose processors and network components. A major asset of considering general purpose products (processors and network components) is an easy technology update, not so obvious when considering dedicated products. In the simplest scheme (see figure 24), there are two layers of processors performing local Feature Extraction (Phase 2) and Global Decision (Phase 3) respectively. Both are managed according to a farm-approach, i.e. individual processors take longer to execute the algorithm than the frequency would require, and have to be sufficiently numerous to allow, by suitable scheduling, to follow the data flow in average. Local processors receive their data from intelligent devices through a switching network. It is assumed in our data model that all data packets have the same length of 1 Kbyte. The global processors receive data from local processors, again through a switch. The data message length here is assumed to be 64 bytes.
Up to now, numerous studies have been devoted to implementing and benchmarking relevant physics algorithms on different processors. As some new products relative to the so-called High Speed Networks emerge on the commercial market, like ATM, Fibre Channel for instance, some studies begin for investigating the potentiality of these new promising technologies, which are all potential candidates and therefore will compete for the final implementation.
Figure 24: Farm-based implementation.
The aim of all the tests performed at ECSEC-Rome, is to evaluate today what is the performance of such general purpose network components and processors, and to try to extrapolate for tomorrow whether it can be suitable to our application or not, and what performance can be expected.
For more details on physics applications, refer to [6], [7], [8] and [9].
Generated with CERN WebMaker