Communication benchmarks with the Ancor Fibre Channel Fabric
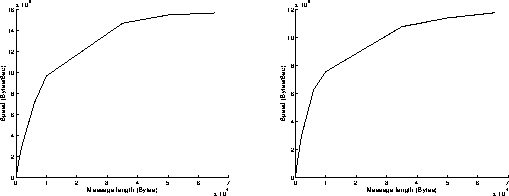
Figure 7a: (left) sender is C10, receiver is 590. (right) sender is 590, receiver is C10.
Figure 7b: (left) sender is C10, receiver is 590. (right) sender is 590, receiver is C10.
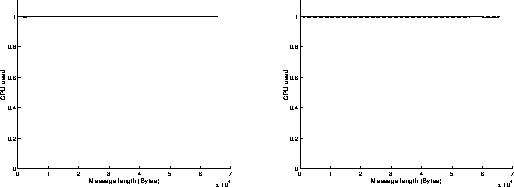
Figure 7c: (left) sender is C10, receiver is 590. (right) sender is 590, receiver is C10.
Figure 8a: (left) sender is C10, receiver is 590. (right) sender is 590, receiver is C10.
Figure 8b: (left) sender is C10, receiver is 590. (right) sender is 590, receiver is C10.
Figure 8c: (left) sender is C10, receiver is 590. (right) sender is 590, receiver is C10.
Figure 9a: (left) sender is C10, receiver is 590. (right) sender is 590, receiver is C10.
Figure 9b: (left) sender is C10, receiver is 590. (right) sender is 590, receiver is C10.
Figure 9c: (left) sender is C10, receiver is 590. (right) sender is 590, receiver is C10.
Figure 10a: (left) sender is C10, receiver is 590. (right) sender is 590, receiver is C10.
Figure 10b: (left) sender is C10, receiver is 590. (right) sender is 590, receiver is C10.
Figure 10c: (left) sender is C10, receiver is 590. (right) sender is 590, receiver is C10.
The concluding remarks made in paragraph III.A.1.e. are still valid here.
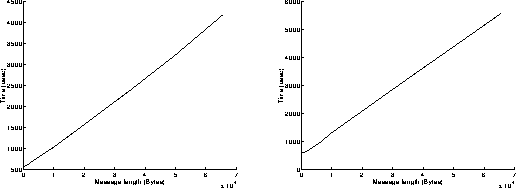
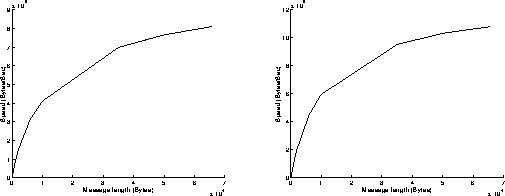
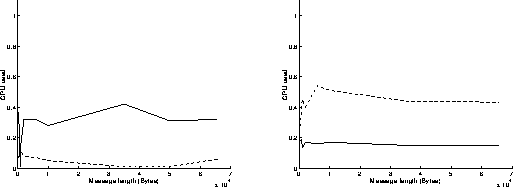
On figures 7, results have been achieved when using the Read and Write functions in a non blocking mode. The best performances are obtained when the most powerful workstation is receiving data (left graphs on figures 7), because the execution of the Read function is slower than the one of the Write function when using non blocking mode. Under these conditions, the overhead of the system is around 575 microseconds, and the speed can reach 15.6 MBytes/s for transmitting 65500 byte messages. Comparing these results to those presented on figures 3 points out the performance improvement induced by the replacement of the 250 workstation by the C10.
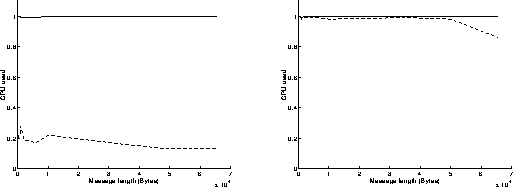
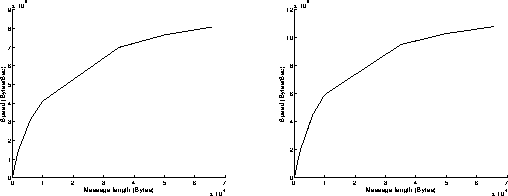
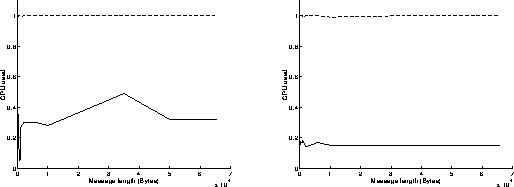
On figures 8, results have been achieved when using the Read function in a blocking mode and the Write function in a non blocking mode. As previously, the best performances are obtained when the most powerful workstation is receiving data (left graphs on figures 8). The results are similar to those obtained on figures 7: the execution of the Read function in a blocking mode takes indeed the same time as if it was achieved in a non blocking mode. On the left graph of figure 8c, we can see that the percentage of CPU time used at the receiver side is below 20 percent: that means that the receiver is sustaining the data flow without any problem and must often wait for data to come in.
On figures 9, results have been achieved when using the Read function in a non blocking mode and the Write function in a blocking mode. Now, the execution of the Write function takes a longer time than the one of the Read function. This explains why the best performances are obtained when the most powerful workstation is sending data (right graphs on figures 9). Under these conditions, the overhead of the system is around 980 microseconds, and the speed can reach 10.8 MBytes/s for transmitting 65500 byte messages.
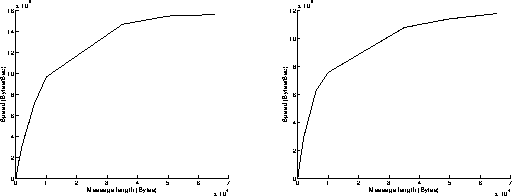
On figures 10, results have been achieved when using the Read and Write functions in a blocking mode. As previously, the best performances are obtained when the most powerful workstation is sending data (right graphs on figures 10). The results are similar to those obtained on figures 9: the execution of the Read function in a blocking mode takes indeed less time than the execution of the Write function in a blocking mode. Under these conditions, the overhead of the system is around 980 microseconds, and the speed can reach 10.8 MBytes/s for transmitting 65500 byte messages.
Generated with WebMaker
Write in a non blocking mode, Read in a blocking mode
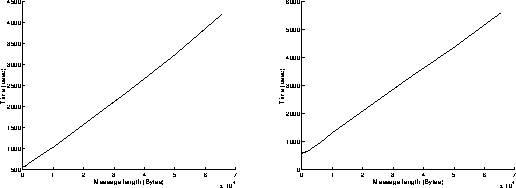
Write in a blocking mode, Read in a non blocking mode
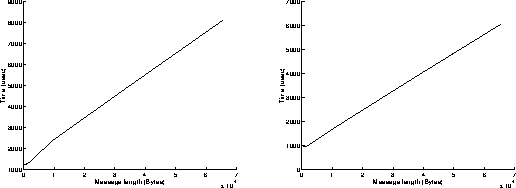
Read/Write in a blocking mode
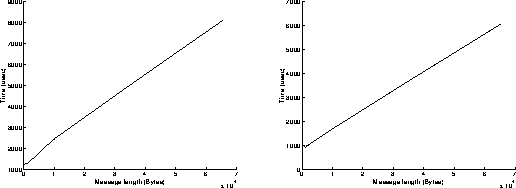
Conclusion
Fabrice Chantemargue - 30 AUG 94
[Next] [Prev] [Top]